





Sztuczna inteligencja (AI) jest obecnie jednym z najbardziej dynamicznie rozwijających się obszarów technologii i jej zastosowanie w e-commerce staje się z każdym dniem coraz bardziej obiecujące. Wiele sklepów internetowych zaczyna dostrzegać potencjał tej technologii i wprowadza ją do codziennej pracy, aby zaoszczędzić czas (swój, jak i klientów), poprawić doświadczenia użytkownika, a także wyniki finansowe, za którymi kryje się ostatecznie przychodowość i rozwój firmy.
Zastosowań sztucznej inteligencji w e-commerce można wymieniać wiele poprzez: automatyzację procesów, personalizację ofert, analizę danych, chatboty do obsługi klienta, systemy do zarządzania zapasami i prognozowania popytu.
Czym jest BigQuery?
Google BigQuery jest działającą w chmurze skalowalną hurtownią danych. Jest zoptymalizowana pod kątem szybkiej analizy danych, dużych danych. Baza danych, którą możesz wykorzystać do wrzucenia lub zaciągnięcia danych z różnych źródeł. Ułatwia on sprawdzenie i analizę.
Takich przykładów mógłbym wymieniać w nieskończoność, a cały artykuł byłby kolejnym w internecie, zawierającym same ogólniki – dlatego przejdźmy do nieco bardziej praktycznych rzeczy jak np. BigQuery (pełni zarządzana, bezserwerowa hurtownia danych Google, która umożliwia skalowalną analizę petabajtów danych) w połączeniu z Performance i ML. BigQuery, które większość kojarzy tylko jako ratunek dla limitu zapytań API w Google Analytics 4, lecz ta hurtownia danych z rodziny Google ma o wiele większe możliwości.
Przykład
Prowadząc rozmowy z różnymi klientami szczególnie z obszaru Performance, spotykamy się często z pytaniem: „Wiem, że nie da się tego konkretnie określić, ale ile na tym zarobię…?”. Możemy podejść do tematu na wiele sposobów: wykorzystać gotowe kalkulatory do estymacji, porównać wyniki podobnych biznesów, (jeśli mamy do nich wgląd) lub wykorzystać BigQuery i uczenie maszynowe w modelu regresji liniowej.
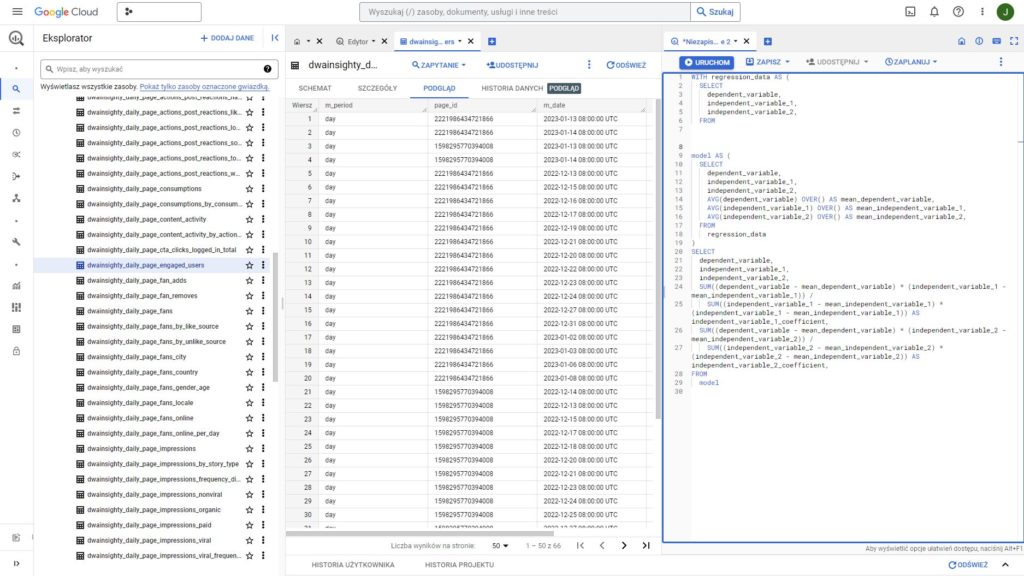
Przekładając to na nieco prostszy język, mowa tutaj o prognozowaniu wartości sprzedaży na podstawie danych dotyczących sprzedaży w poprzednich okresach. Celowo w poprzednim zdaniu podkreśliłem słowo „dane”, ponieważ stanowią one dla nas fundamenty w trenowaniu modelu. Bez nich trudne będzie wiarygodne estymowanie wyników.
Ciekawostka: Z jednej strony w kontekście danych można powiedzieć, że „im więcej, tym lepiej”, natomiast nie zawsze, jeśli mówimy o ML – dlaczego? Na ten temat można napisać całkiem osobny artykuł, ale pracując z modelami ML musimy pamiętać, aby dobierać tylko te metryki dla konkretnych przykładów, które rzeczywiście mogą przyczynić się do uwiarygodnienia prognozy. W przeciwnym wypadku spodziewajcie się mało wiarygodnych wyników oraz dużego obciążenia Waszego Billing ID za zużycie zbyt dużej mocy obliczeniowej.
Wybór zmiennej
Kolejnym krokiem powinno być wybranie wśród metryk zmiennej docelowej i zmiennych objaśniających. Chodzi o wskazanie, którą zmienną chcemy przewidywać (zmienna docelowa) oraz, które zmienne będą używane do przewidywania (zmienne objaśniające). Tak przygotowane zasoby w kolejnym etapie rozpoczynają trenowanie, aby następnie przejść przez proces walidacji w celu oceny jakości.
Na samym końcu po eksporcie otrzymujemy model, który możemy użyć, aby poprawić np. jeszcze bardziej jego jakość. Innymi słowy, po predykcji, dane z predykcji i dane historyczne mogą być wykorzystywane do trenowania modelu i ulepszania jego jakości, co pozwala na lepsze prognozowanie w przyszłości.
Warto pamiętać, że proces szkolenia modelu może być powtarzany kilkukrotnie, aby uzyskać jak najlepsze wyniki. Jest to przykład dosyć prostego modelu, który możemy wykorzystać w ramach BigQuery ML, natomiast sama hurtownia poza modelem regresji liniowej wspiera także nieco bardziej rozbudowane modele:
1. Drzewo decyzyjne
2. Modele gradient boosting
3. Modele deep learning (sieć neuronowa)
4. Modele klastrowania (KMeans)
5. Modele asocjacyjne (APRIORI)
Takim sposobem otrzymujemy dosyć wiarygodną (w zależności od użytych danych) odpowiedź dla naszego klienta!
Podsumowanie
Prognozowanie sprzedaży czy też popytu z wykorzystaniem sztucznej inteligencji jest coraz popularniejszym rozwiązaniem w e-commerce. Dzięki takim działaniom sklepy internetowe mogą lepiej planować zamówienia i zarządzać magazynem, co pozwala na oszczędności kosztów i zwiększenie efektywności. Jednak, aby skutecznie prognozować sprzedaż, ważne jest posiadanie wystarczających danych historycznych z uwzględnieniem zmienności popytu.

Jakub Rojek
Performance Specialist w firmie Tigers odpowiedzialny za wdrożenia chmurowe w obszarze Big Data. W wolnych chwilach udaje sushi mastera.







